
RPC调用失败情况分析
RPC 调用失败可以分为三种情况:
- RPC 请求还没有离开客户端
- RPC 请求到达服务器,但是服务器的应用逻辑还没有处理该请求
- 服务器应用逻辑开始处理请求,并且处理失败

最后一种情况是通过 server config 配置的重试策略来处理的,是本文主要讲解的内容
而对于前两种情况,gRPC 客户端会自动重试,与重试策略的配置并没有太大关系
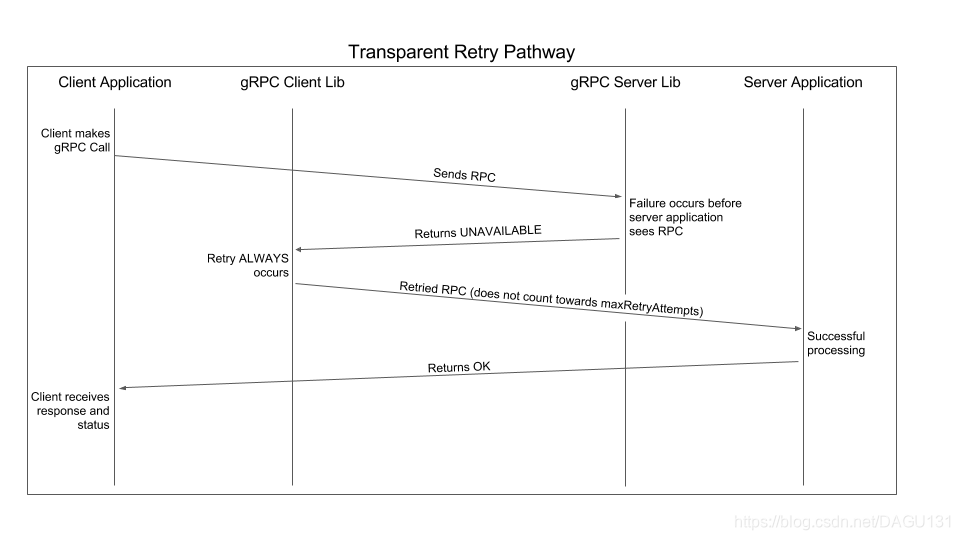
因为这两种情况,服务端的逻辑并没有开始处理请求,所以始终可以重试,也被称为透明重试(transparent retries)
-
对于第一种情况,因为RPC没有离开客户端,所以可以一直重试,直到成功或者直到RPC的截止时间为止
-
对于第二种情况,虽然RPC 到达了服务端,但是应用逻辑并没有处理请求,所以,客户端会立即重试一次,如果再次失败, RPC 将根据配置的重试策略来进行处理
注意,这种情况可能会增加链路上的负载
下文介绍的重试限流只是为了防止服务器的应用逻辑服务过载,而这些重试并且不会进入应用逻辑层,所以他们不会把他们算作失败
同样透明重试也不会受到的重试配置 maxAttempts 限制
service config 简介
客户端的重试机制和重试限流都是通过 service config 来配置的,所以这里简单介绍一下 service config
service config 机制允许服务提供者发布参数,让其所有客户端自动使用
service config 的格式可以参考 grpc.service_config.ServiceConfig protocol buffer message, 未来可能会引入新的字段
会在其他文章中,讲一下服务端配置 service config 相关的知识
需要注意的是,service config 是和服务名称绑定的,客户端名称解析插件解析服务名,会返回解析的地址和 service config
名称解析返回给 grpc client 是 json 格式的 service config
客户端设置默认 service config
在客户端创建gRPC 连接时,通过DailOption 也可以配置一个默认的 service config
func WithDefaultServiceConfig(s string) DialOption
传递的参数是 json 格式化的字符串
客户端配置的默认service config 在使用上有一些限制:
- DialOption
WithDisableServiceConfig被调用,会屏蔽掉服务器设置的 service config ,客户端会使用默认 service config - 当 name resolver 解析服务名称时,没有返回 service config 或者 返回一个
invalid service config
retryPolicy = `{
"methodConfig": [{
"name": [{"service": "grpc.examples.echo.Echo"}],
"waitForReady": true,
"retryPolicy": {
"MaxAttempts": 4,
"InitialBackoff": ".01s",
"MaxBackoff": ".01s",
"BackoffMultiplier": 1.0,
"RetryableStatusCodes": [ "UNAVAILABLE" ]
}
}]}`
_, err := grpc.Dial(*addr, grpc.WithInsecure(), grpc.WithDefaultServiceConfig(retryPolicy))
重试策略
gRPC 的重试策略有两种分别是 重试(retryPolicy)和对冲(hedging)
一个RPC方法只能配置一种重试策略
当失败和成功的比例超过阈值时,gRPC 又提供了一种重试限流机制来限制重试和对冲,防止造成服务器过载
服务器还可以设置指定的重试延迟或者取消重试,被称为Pushback
透明重试会在服务端的应用逻辑并没有接收到请求的时候,gRPC 还会进行自动的重试
重试 retryPolicy
service config 配置
// 最多执行四次 RPC 请求,一个原始请求,三个重试请求,并且只有状态码为 `UNAVAILABLE` 时才重试
"retryPolicy":{
"maxAttempts": 4,
"initialBackoff": "0.1s",
"maxBackoff": "1s",
"backoffMutiplier": 2,
"retryableStatusCodes": [
"UNAVAILABLE"
]
}
重试会根据请求返回的状态码是否符合 retryableStatusCodes来进行重试请求
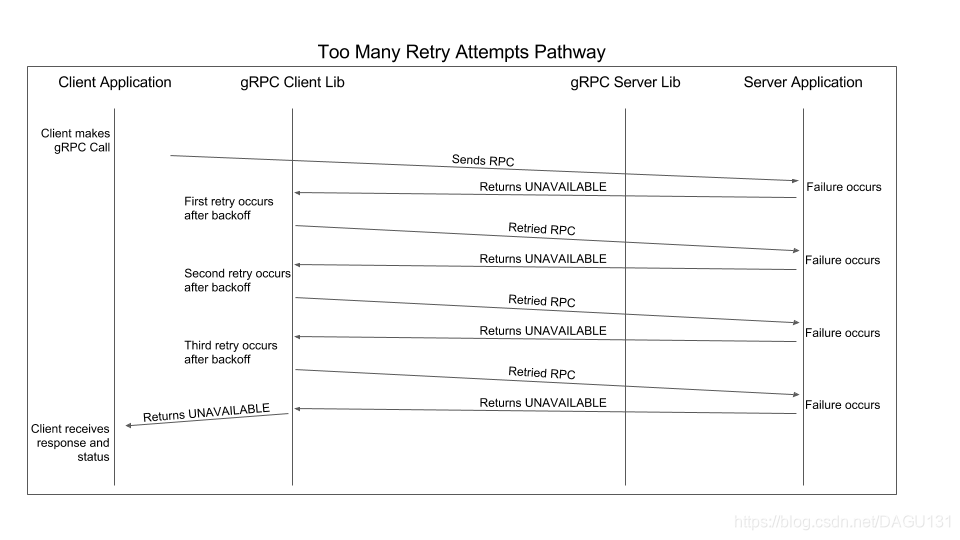
最大重试次数 maxAttempts
指定一次RPC 调用中最多的请求次数,包括第一次请求
如果设置了调用的过期时间,那么到了过期时间,无论重试情况如果都会返回超时错误DeadlineExceeded
指数退避
在进行下一次重试请求前,会计算需要等待的时间
- 第一次重试间隔是
random(0, initialBackoff) - 第 n 次的重试间隔为
random(0, min( initialBackoff*backoffMultiplier**(n-1) , maxBackoff))
重试状态码 retryableStatusCode
当 RPC 调用返回非 OK 响应,会根据 retryableStatusCode 来判断是否进行重试
通常,只有表明服务逻辑没有处理请求的状态码才应该进行重试,如果服务提供了幂等或者可以安全的多次请求时,那么就可以指定更详细的参数
比如,删除资源的 RPC 调用失败,并返回了
INTERNAL错误码,那么可能在返回错误前就已经删除了资源
如果该方法是幂等的,那么进行重试就没什么问题,否则,重试就可能会导致一些异常问题
retryPolicy 参数要求
maxAttempts必须是大于 1 的整数,对于大于5的值会被视为5initialBackoff和maxBackoff必须指定,并且必须具有大于0backoffMultiplier必须指定,并且大于零retryableStatusCodes必须制定为状态码的数据,不能为空,并且没有状态码必须是有效的 gPRC 状态码,可以是整数形式,并且不区分大小写 ([14], ["UNAVAILABLE"], ["unavailable")
对冲策略 HedgingPolicy
service config 配置
// RPC 调用最多发送 4 次请求,每次间隔 0.5s
// 如果没有指定 hedgingDelay 或者为 “0s" 的话,就同时发送四个 请求
"hedgingPolicy":{
"maxAttempts": 4,
"hedgingDelay": "0.5s",
"nonFatalStatusCodes":[
"UNAVAILABLE",
"INTERNAL",
"ABORTED"
]
}
对冲是指在不等待响应的情况主动发送单次调用的多个请求
如果一个方法使用对冲策略,那么首先会像正常的 RPC 调用一样发送第一次请求,如果hedgingDelay时间内没有响应,那么直接发送第二次请求,以此类推,知道发送了 maxAttempts 次
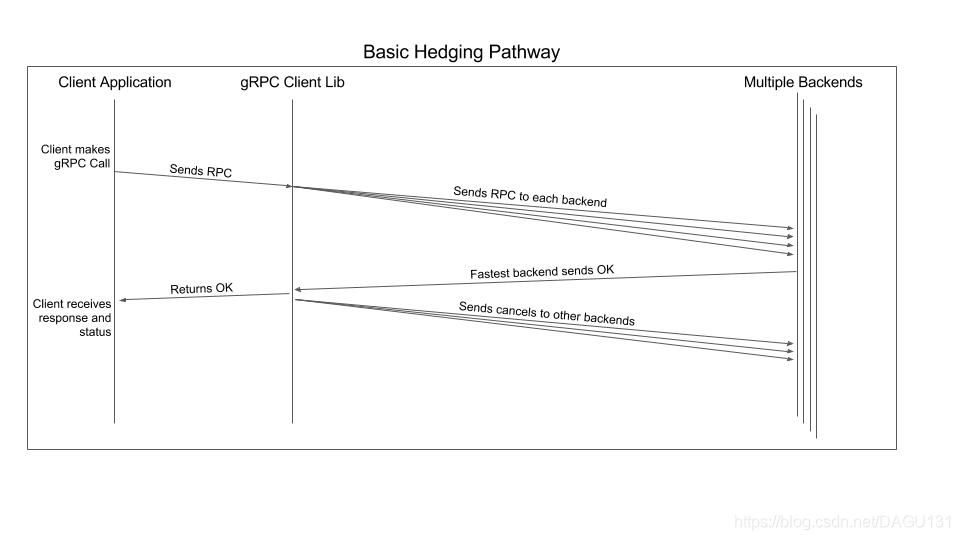
注意: 使用对冲的时候,请求可能会访问到不同的后端(如果设置了负载均衡),那么就要求方法在多次执行下是安全,并且符合预期的
与retryPolicy 一样,对冲也会受到调用过期时间的影响,过期时间到了那么直接返回DeadlineExceeded
当对冲请求接收到 nonFatalStatusCodes后,会立即发送下一个对冲请求,不管 hedgingDelay
如果受到其他的状态码,则所有未完成的对冲请求都将被取消,并且将状态码返回给调用者
本质上,对冲可以看做是受到 FatalStatusCodes 前对 RPC 调用的重试
验证参数
- maxAttempts 必须是大于 1 的整数,对于大于5的值会被视为5
- hedgingDelay 为可选字段,必须按照 proto3 Duration 类型
- nonFatalStatusCodes 是可选的字段,为什么是可选的呢,因为在上一个请求没有响应的时候也会发送对冲请求
如果没有指定 hedgingDelay 或者为 “0s" 的话,就同时发送四个 请求
重试限流
当客户端的失败和成功比超过某个阈值时,gRPC 会通过禁用这些重试策略来防止由于重试导致服务器过载
service config 配置
"retryThrottling":{
"maxTokens": 10,
"tokenRatio": 0.1
}
重试限流是根据服务器来设置的,而不是针对方法或者服务
对于每一个服务器,gRPC 客户端会维护一个 token_count 变量,最初设置为 maxToken , 值的范围是 0 - maxToken
对于每个 RPC 请求都会对 token_count 产生一下效果
- 每个失败的 RPC 请求都会递减token_count 1
- 成功 RPC 将会递增
token_counttokenRatio
需要注意这里的失败 RPC 是指返回的状态码符合retryableStatusCodes,nonFatalStatusCodes或者服务器回推通知不在重试的RPC
如果 token_count <= ( maxTokens / 2), 则关闭重试策略,直到 token_count > (maxTokens/2),恢复重试
对于对冲 RPC,发送第一个RPC请求后,如果 token_count 大于(maxTokens/2),才会发送后续的对冲请求
当 token_count <= ( maxTokens / 2) 时,重试请求会被取消,并且将状态码返回给调用者
验证
- maxTokens 必须制定,并且必须在(0, 1000] 范围
- tokenRatio 必须,并且必须大于0的浮点数,超过三位的小数会被忽略
服务器回推(Pushback)
服务器Pushback可以通过 metadata 告诉客户端在给定的延迟后重试,或者根本不重试
如果客户端已经用尽了 maxAttempt,那么即使服务器说在给定的延迟后重试,也不会再重试了
对于对冲请求,如果 Pushback 拒绝重试,那么就不会发送下一次的对冲请求,如果Pushback 指定了在给定延迟后再重试,那么对冲请求会在给定的延迟后重试(如果重试次数没有超过 maxAttempts)
grpc-retyr-pushback-ms 将作为服务器Pushback 的metadata key,该值为 int32的 unicode(没有前导0)
表示下次重试需要等待多少秒,如果为负数或者不可解析,则表示不要重试
重试配置与 metadata
禁用重试
如果服务端在service config 中配置了重试策略,但是客户端并不想使用重试策略,可以在创建 gRPC 连接时传递 DialOption
func WithDisableRetry() DialOption
注意: 这不会影响透明重试
客户端是默认关闭了重试的,需要在环境变量中设置 GRPC_GO_RETRY=on 来开启重试
获取重试次数
与重试相关的 metadata key 除了上文介绍的 grpc-retyr-pushback-ms ,还有 grpc-previous-rpc-attempts
grpc 的客户端和服务端都可以通过 grpc-previous-rpc-attempts metadata key 来获取到上一次的重试次数,在第一个RPC请求上是不存在的,第二个请求为1
流式 RPC 的重试
outgoing message 是指客户端在于服务器连接器上发送的所有消息
对于一元 RPC和服务端 streaming RPC ,outgoing message是单个消息
对于 客户端 streaming RPC 和双向流 RPC,outgoing message 就是打开连接后客户端发送的整个消息流
grpc 客户端会缓冲传出消息,并且只要传出消息全部都在缓冲区,就可以重新发送和重试
但是当传出消息太大而无法缓冲的时候,重试就会无效
grpc客户端支持用于重试的内存限制
对于单个调用可以通过 CallOption 设置
func MaxRetryRPCBufferSize(bytes int) CallOption
service config 重试配置
{
"methodConfig": [{
"name": [{"service": "grpc.examples.echo.Echo"}],
"waitForReady": true,
"retryPolicy": {
"MaxAttempts": 4,
"InitialBackoff": ".01s",
"MaxBackoff": ".01s",
"BackoffMultiplier": 1.0,
"RetryableStatusCodes": [ "UNAVAILABLE" ]
}
}]}
"retryThrottling": {
"maxTokens": 10,
"tokenRatio": 0.1
}
注意retryThrottling 限流配置是针对整个服务器的
参考:gRPC Retry Design
example: Retry